一次疑难杂症的记录
近期在项目上遇到一个问题,折腾许久,比较棘手,最后以比较简单暴力的方式解决了,做个记录。
一、背景
环境是三台 Tencent OS 服务器,各使用一张双口OCP 网卡(100G 端口),为搬迁来的旧机器。原有业务在运行,客户表示已经清配置,要重新部署业务系统。
服务器配置本身不复杂。客户提供了 bond 配置内容和软件包,理论上虚拟 KVM 接上后配置 bond 并重启 network 即可通讯,然后可传软件包执行初始化配置。结果第一步就翻车——服务器能启动、找到启动项、选择内核后黑屏。
二、启动问题排查
起初怀疑虚拟 KVM 有问题,让现场工程师接显示器测试,发现同样黑屏。使用 Alpine Linux 测试则可正常启动。
查看 GRUB 内容如下:
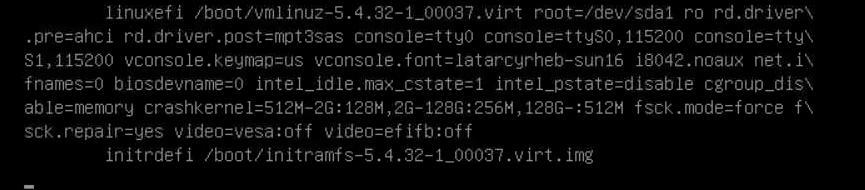
尝试进入单用户模式仍为黑屏。再次重启并删掉以下字段后,系统可正常输出显示:
1 | |
进入系统后执行以下操作:
1 | |
系统重启成功。
三、Bond 配置
按客户提供的配置进行:
eth0
1 | |
eth1
1 | |
bond1
1 | |
执行:
1 | |
确认 IP 已配置到 bond1 上。ARP 双发正常,无需额外配置。
四、配置残留问题
写配置时发现客户声称“重装过”的系统仍保留旧 IP 配置,SSH 配置也监听旧 IP 和高位端口,说明系统并未真正清理干净,给后续排查带来误导。
担心的地方在于不知道这个OS有没有做其它部分的深度定制,也不知道旧配置有没有真的清掉,所以联系了客户,但没有得到有效帮助。
五、异常现象
三台主机配置一致,但状态如下:
| 主机 | eth0 | eth1 |
|---|---|---|
| server1 | down | down |
| server2 | down → up | up |
| server3 | down | down |
过一段时间后 server2 的 eth0 也 up,其他两台仍 down。多次重启无效。
尝试强制速率:
1 | |
无效。端口状态为 unknown,BMC 无报错,硬件状态正常。
六、逐项排除
配置文件问题
检查/etc/sysconfig/network-scripts/和/etc/udev/rules.d/70-*正常,三台一致,与客户提供无差别。
配置文件问题排除驱动与固件问题
查看dmesg和message没有发现异常,和客户确认了其它相同项目配置、驱动、固件一致。
驱动与固件问题排除(根据后面结果来看,固件存疑)配置与系统问题
使用 Alpine Linux 临时引导,端口状态也是down,模块不亮,说明和系统无关。
使用客户提供的Tencentos镜像重装server1,仍down,说明和系统内残留配置无关。
配置与系统问题排除物理线缆与模块问题
测试把server2的ocp网卡和server1交换,交换后状态如下:
server1开始只up eth1,约6小时后,eth0也up;
server2 eth0/1 down症状表现是跟着网卡走,认为就是物理状态问题,交换机侧查看光衰,发现down端口有一个光衰太高,现场安排使用mpo清洁棒进行了清洁,略有改善,但仍无法链接。此时怀疑对象是模块和线都被污染,于是再次安排换模块换线,未解决。
这个时候已经怀疑是现场人员操作手法问题,是不是有不好的习惯会碰到接头,安排了另一位布线老手去现场重新飞线,飞线换模块后,server3的光衰降低,端口也起来了,但在没做任何操作的情况下,其他又down了,非常诡异。但经过飞线测试,线缆的状态问题已排除
物理模块与线缆问题排除自环测试
再次尝试自环,发现自环之后所有端口都能立即up,由此又把网卡/模块的物理状态问题排除。。
物理层问题排除自动协商测试
最后又回到交换机端,再次检查端口速率协商,lacp等,均正常,但现在开始怀疑到协商问题,回到server端,想起来之前强制指定过速率,ethtool中看到Auto-negotiation: off,想尝试一下开启自动协商,执行命令:1
ethtool -s eth1 autoneg on端口当场 down,每一台主机都是这样,改回off也需长时间等待才能 up。,而开启自动协商的端口,等待几小时后也没有up。
协商机制异常
七、更换网卡
目前情况是:
配置文件正常
驱动与固件正常
系统正常
物理状态正常
协商失败
鉴于目前的复杂情况,客户安排厂商工程师上门更换网卡尝试。
厂商工程师上门,尝试收集日志时,又遇到了以下情况:
- Boot U 盘无法启动,改 BIOS 为 Legacy 后卡死;
- 拔电 30 秒、长按电源键,上电仍失败;
- 拆机取下 CMOS 电池放电后恢复;
- 收集系统与 BMC 日志包。
次日更换新网卡后,端口立即点亮,状态 up。
进入系统,查看新网卡固件版本,发现较新一些,考虑到三张网卡同时坏的可能性其实并不大,我个人倾向于是固件版本不匹配(即使客户说其它项目都是相同的,但根据客户在这项目所有事情中表现出的不专业性,提供的手册的错漏百出来看,已经不可信了)。
固件信息如下:
旧网卡
1 | |
新网卡
1 | |
另外,更换网卡后,由于发生了配置重载,所以自动协商状态也是on,可以正常协商,此前一开自动协商就down明显也是有问题的。
更换新卡后恢复正常,自动协商状态为 on,bond 通讯稳定。
八、最终处理
降级固件:
由于新网卡的固件版本较高,不符合交付需求,所以需要降级处理,这个时候已经猜测到降级会导致网口down了,提出之后客户仍表示高版本固件无法适配后续流程,必须降级安装mft工具:
1 | |
烧录并重启:
1 | |
然后服务器果不其然的连不上了。。
恢复处理
找三线,收日志,sysinfo 和mstdump,结论是”网卡端口没有up事件发生,一直处于polling状态,这一般是cable/模块没有插好、或物理link协商失败造成的。”查看模块信息:
1
mlxlink -d 41:00.0 -m --cable --dump --show_serdes_tx --rx_fec_histogram --show_histogram -c发现输出中模块为指定厂商,但芯片型号非此前业务测试使用的,应该是厂商的不同代工厂货不同批次使用芯片不同
1
2Vendor Name HISILICON
Vendor PartNumber OM3538SX101-H3C确认后,更换成光迅的模块,端口UP,复测正常
九、总结
一个模块型号与驱动不匹配引起的问题,表现在了全链路上,期间产生各种复杂现象,最终还是回归到了最简单的物理问题。
许多复杂故障都是这样,苦寻许久,最后回到最简单的部分。